Indices alfabéticos, jerarquías, frecuencia de uso y tag cloud
13 de marzo, 2007 por Catuxa
En un principio lo teníamos muy claro, la información se ordenaba de manera alfabética (a b c d …) cuando la información era demasiada, se otorgó una clasificación jerárquica y dentro de ésta ordenábamos por orden alfabético (1.Arte 1.1. Arte abstracto 1.2. Arte Moderno), y cuando la información se hizo incontrolable e infinita, (sobre todo con la explosión documental de la era electrónica) tuvimos que recurrir a nuevas formas de clasificar, categorizar, describir y visualizar la información. Y aquí no podemos obviar el poder que los sistemas de clasificación colaborativa (el tagging y las folksonomías) ofrecen a la hora de paliar nuestros problemas de infoxificación.
Ahora tenemos a nuestro alcance varias formas para representar la información y navegar por ella, ¿cuál es la mejor para tí?, para evitarse esta pregunta, Michael Angeles, un arquitecto de información especializado en el desarrollo de sitios web y productos enfocados a la comunidad bibliotecaria, nos ofrece en su weblog la posibilidad de navegar (browse) por los contenidos desde 4 puntos de acceso y de buscar información entre sus contenidos por medio de un buscador (search).

Me maravillan estas 4 formas de navegar, ojear y bucear por su blog:
Obviando la última, que supongo que se trata de una clasificación subjetiva (resultado de lo que a Michael le parece más interesante), las otras tres representan bajo 3 criterios distintos toda la información del blog, para responder a tres necesidades diferentes para cada usuario o para cada momento dado.
- Busco un post que se llamaba Library Web Site Meets About.com, así que utilizo en índice alfabético, pincho en la L y navego por todos los post que empiezan por L.
- Busco post sobre XML, navego por las categorías jerárquicas, llego a la dedicada a XML y puedo ir navegando por las subcategorías que deriban de ésta por lo que me entero que el Atom – RSS, el RDF, el FOAF, etc, son términos que tienen que ver con lo que yo buscaba… y encima si me interesa de manera especial cualquiera de estas categorías y subcategorías, me ofrecen la posibilidad de sindicarlas de manera individual!!!
- Yo no tengo ni idea de qué trata este blog, ni tengo tiempo para empezar a leer secciones, así que me voy a ver la tag cloud y de un primer vistazo me entero que de lo que más escribe en su blog este arquitecto de información es de Information Architecture and Interaction Design, y de Visual design entre otros temas.

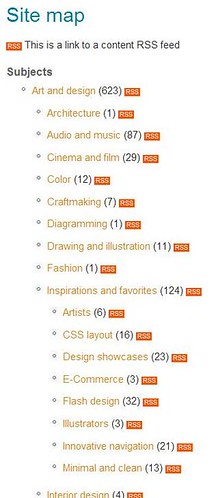

Me ha parecido impresionantemente útil, y sencillo, y si ésto se puede hacer en un blog o publicación personal, en donde la información es más o menos “controlable”, os imaginais las posibilidades que puede tener un sistema de navegación así en los OPACS y catálogo de las bibliotecas???
… y es que cada usuario tiene diferentes necesidades de navegación en diferentes momentos y circunstancias…
POST RELACIONADOS:
- Integrando la folksonomía en los catálogos de las bibliotecas
- Indización social y recuperación de información
- Mapa de temas en The Guardian
Muy muy interesante.
Precisamente hoy en el curro le he estado dando muchas vueltas al manejo ingente de información, y algunas de las cosas de las que hablas en el post me parecen un buen punto de partida.
Muy buena entrada, y muy interesante. Aunque personalmente las folksonomias y las chinchetas (tags) no terminan de gustarme, el motivo de que no me gusten es que se pueden “hackear” de igual manera que se puede “hackear” Google para forzarle a un mejor posicionamiento web.
Además no solo es bueno ver las bondades de las tecnologías, también tenemos que ver sus debilidades.
En el caso de las chinchetas (tags) y folksonomías como ya he dicho se pueden forzar para que tengan mayor importancia de la que tienen. Recordemos que ya se han destapado falsos blogs de publicidad viral, en los que se buscaba dar preeminencia en algunas cosas sobre otras.
Sobre las categorías alfabética, me parece la mejor, aunque también es cierto que ha veces conocemos las cosas por diferentes nombres, lo mejor sería desde mi punto de vista serían categorías alfabéticas con un lenguaje controlado, no con un lenguaje natural.
La segunda opción, mapa del sitio, es la que me da más miedo, por lo mismo, lenguaje natural, y luego asociación de ideas o recursos por parte del autor, sería necesario montar un mapa de sitio mediante un mapa conceptual interactivo 3d que nos permita observar mucho mejor toda la web.
Pero recordemos, no poder tener debilidades no deja de ser muy buenas opciones a la hora de organizar el conocimiento de un sitio web.
Me alegro que te resulte útil, Daniel!
Oskar muy buena apreciación, como siempre, pero no estoy del todo de acuerdo en el tema de los problemas de las folksonomías, ya buscaré algunos ejemplos que demuestran lo contrario, y seguimos discutiendo.
He estado buscando los post que te comentaba, Oskar, sobre el spam en las tags, de lo que nos hablaba Vane hace tiempo, cuando empezaban a proliferar los artículos y comentarios sobre éstos sistemas.
Yo creo que a la vista de productos como citeulike, delicious, o flickr, y después de que pasase un tiempo prudencial para valorar su efectividad, está claro que no debemos temer al problema del spam en las tags. El usuario, el mayor beneficiario del tagging, NO LO PERMITIRÍA